1、下载strimzi
一定要下载与k8s同版本的strimzi的版本,我的k8s版本是v1.21.5,因此选用0.36版本。
wget https://github.com/strimzi/strimzi-kafka-operator/releases/download/0.36.0/strimzi-0.36.0.tar.gztar zxvf strimzi-0.36.0.tar.gz
cd /root/deploy/kafka/strimzi-0.36.02、替换一些镜像地址
查找出所有镜像,将其替换为不需要科学上网的私服地址
grep -r "image: quay.io/strimzi" .可以使用下面的命令进行替换为你自己的私服镜像地址
grep -rl "quay.io/strimzi/operator:0.36.0" . | xargs sed -i 's|quay.io/strimzi/operator:0.36.0|hb.xxxx.com/library/strimzi/operator:0.36.0|g'
grep -rl "quay.io/strimzi/drain-cleaner:0.5.0" . | xargs sed -i 's|quay.io/strimzi/drain-cleaner:0.5.0|hb.xxxx.com/library/strimzi/drain-cleaner:0.5.0|g'
grep -rl "quay.io/strimzi/canary:0.6.0" . | xargs sed -i 's|quay.io/strimzi/canary:0.6.0|hb.xxxx.com/library/strimzi/canary:0.6.0|g'3、安装 CRD 、RBAC 资源及kafka集群控制器(用于自动构建kafa集群)
kubectl create namespace kafka
#替换安装文件中的命名空间
sed -i 's/namespace: .*/namespace: kafka/' install/cluster-operator/*RoleBinding*.yaml
kubectl create -f install/cluster-operator -n kafka
kubectl get deployments -n kafka
4、创建kafka集群
使用examples中的示例文件,创建一个使用永久存储,三个zk,三个kafka的集群
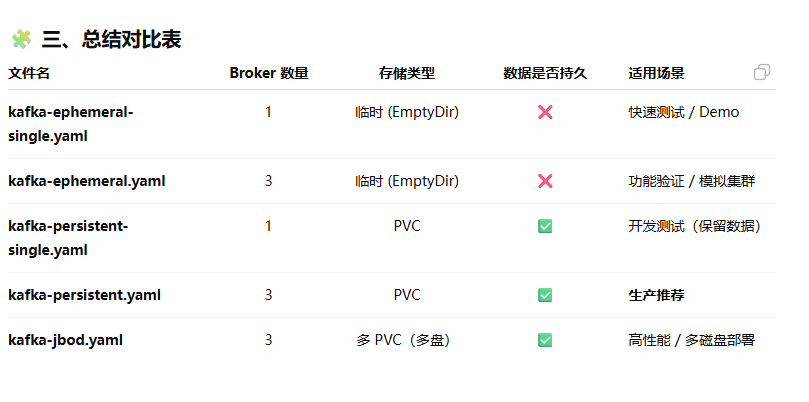
cp examples/kafka/kafka-jbod.yaml ./编辑kafka-jbod.yaml文件,添加命名空间并指定私服中的kafka镜像
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: kafka-cluster
namespace: kafka
spec:
kafka:
version: 3.5.0
replicas: 3
template:
pod:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: strimzi.io/name
operator: In
values:
- kafka-cluster-kafka
topologyKey: "kubernetes.io/hostname"
image: hb.xxxx.com/library/strimzi/kafka:0.36.0-kafka-3.5.0
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
- name: external
port: 9094
type: nodeport
tls: false
configuration:
brokers:
- broker: 0
advertisedHost: 192.168.88.21
advertisedPort: 32317
- broker: 1
advertisedHost: 192.168.88.21
advertisedPort: 30093
- broker: 2
advertisedHost: 192.168.88.21
advertisedPort: 32367
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
inter.broker.protocol.version: "3.5"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
zookeeper:
replicas: 3
template:
pod:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: strimzi.io/name
operator: In
values:
- kafka-cluster-zookeeper
topologyKey: "kubernetes.io/hostname"
storage:
type: persistent-claim
size: 100Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}- 修改创建资源的命名空间
- 如果不需要对外提供维护服务,可以将nodeport部分删除
- template.pod.affinity.podAntiAffinity:配置kafka及zookeeper的pod亲后度,避免将所有的pod都部署到一个节点上
- 另外一定要注意:你的storageclass的VOLUMEBINDINGMODE模式必须是WaitForFirstConsumer,否则会导致创建afka的pvc时遇到问题,也可能造成所有的集群节点(kafka及zookeeper)都会分配到一个node节点上
- advertisedHost:如果你想用其中的一个节点的vpn服务对外提供nodeport服务,那么就需要你配置advertisedHost字段。ip地址是你想对外提供服务的vpn的地址;端口号是strimzi随机生成的nodeport地址,你可以随意设置创建完集群后通过kubectl get pods -n kafka查看这些ip,再新到文件后执行kubectl apply -f ./xxx.yaml来自动生效。
创建集群
kubectl apply -f ./kafka-jbod.yaml5、配置nginx
stream {
#kakfa
upstream kafka30005 {
hash $remote_addr consistent;
server k8s1:30343 weight=5 max_fails=1 fail_timeout=10s;
server k8s2:30343 weight=5 max_fails=1 fail_timeout=10s;
server k8s3:30343 weight=5 max_fails=1 fail_timeout=10s;
server k8s1:32679 weight=5 max_fails=1 fail_timeout=10s;
server k8s2:32679 weight=5 max_fails=1 fail_timeout=10s;
server k8s3:32679 weight=5 max_fails=1 fail_timeout=10s;
server k8s1:30049 weight=5 max_fails=1 fail_timeout=10s;
server k8s2:30049 weight=5 max_fails=1 fail_timeout=10s;
server k8s3:30049 weight=5 max_fails=1 fail_timeout=10s;
}
server {
listen 30005;
proxy_connect_timeout 5s;
proxy_timeout 10s;
proxy_pass kafka30005;
}
}strimzi会为每个broker创建不同的nodeport端口,而且这些端口也是随机的,我们可以使用【kubectl get svc -n kafka】查看所有的service并找出对应的nodeport端口号。

6、测试
(1)在同一个k8s集群中运行kafka容器进行测试
#创建并进入kafka测试pod
kubectl run kafka-test -n kafka --rm -ti --image=hb.xxxx.com/library/strimzi/kafka:0.36.0-kafka-3.5.0 -- bash
#列出所有的主题
bin/kafka-topics.sh --bootstrap-server kafka-cluster-kafka-bootstrap:9092 --list
#发送测试消息
echo "Hello Kafka! 这是我的第一条消息!" | bin/kafka-console-producer.sh --bootstrap-server kafka-cluster-kafka-bootstrap:9092 --topic quickstart-events
#消费上面的测试消息
bin/kafka-console-consumer.sh --bootstrap-server kafka-cluster-kafka-bootstrap:9092 --topic quickstart-events --from-beginning(2)使用linux下的kafa客户端
下载kafka_2.13-4.1.0.tgz后运行相关命令
bin/kafka-topics.sh --bootstrap-server 192.168.3.109:31092 --list7、相关文档
https://strimzi.io/docs/operators/0.36.0/deploying.html#cluster-operator-str