1、通过ollama安装
本地运行如此庞大的模型可能具有挑战性,需要大量的计算资源和技术专业知识。幸运的是,很多厂商和开源社区纷纷开发了非常高效的大模型部署和应用工具。 Ollama 就是其中一个用户友好的解决方案,它优化了设置和配置细节,包括 GPU 使用情况,使开发人员和研究人员更容易在本地运行大型语言模型。Ollama 支持各种模型,包括 Llama 3,让用户能够探索和实验这些尖端的语言模型,而无需复杂的设置过程。
我们打开官方网站:https://ollama.com/download
根据一般规律,3B模型需要8G内存,7B模型需要16G内存,13B模型需要32G内存,笔者主机显卡是4070Ti 12G,只能选择7B模型(4bit量化版),在运行的Shell窗口中输入命令,ollma run llama3:wnload,下载Ollama。
ollama run llama3.1
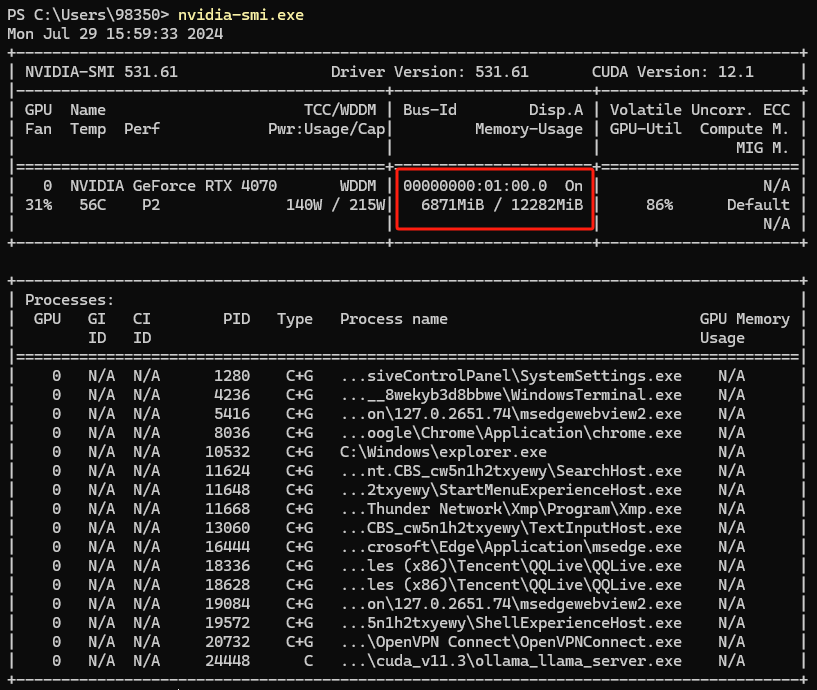
查看GPU内存使用情况:
2、安装UI界面——Saddle
项目下载地址
https://github.com/jikkuatwork/saddlenginx配置
server {
listen 9004;
server_name chatgpt.baidu.com;
client_max_body_size 81920M;
location / {
root /opt/nginx/html/saddle-master;
try_files $uri /index.html;
}
location /api {
#为ollama的api调用添加用户验证
auth_basic "Restricted Content";
auth_basic_user_file ollama-api.password;
proxy_read_timeout 3500;
proxy_connect_timeout 3250;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header SSL_PROTOCOL $ssl_protocol;
proxy_pass http://192.168.58.27:11434;
}
}2、更改Saddle的ollama的api地址
# vim /opt/nginx/html/saddle-master/Saddle.js
api(action = "generate") {
return `http://localhost:${this.port}/api/${action}`
}变更为
api(action = "generate") {
return `/api/${action}`
}ollama-ui
https://github.com/ollama-ui/ollama-uihttps://developer.baidu.com/article/details/3226220
https://www.53ai.com/news/finetuning/2024073031045.html
https://gitee.com/achuo/ollama?skip_mobile=true#https://gitee.com/link?target=https%3A%2F%2Fgithub.com%2Frtcfirefly%2Follama-ui
https://www.allbrightlaw.com/CN/10475/c913ec0c1b3080ce.aspx
#api
https://ollama.fan/reference/api/#generate-a-chat-completion-request-with-image